




院况简介


1949年,伴随着新中国的诞生,中国科学院成立。
作为国家在科学技术方面的最高学术机构和全国自然科学与高新技术的综合研究与发展中心,建院以来,中国科学院时刻牢记使命,与科学共进,与祖国同行,以国家富强、人民幸福为己任,人才辈出,硕果累累,为我国科技进步、经济社会发展和国家安全做出了不可替代的重要贡献。 更多简介 +
院领导集体
创新单元
科技奖励
科技期刊
科技专项
中国科学院院级科技专项体系包括战略性先导科技专项、重点部署科研专项、科技人才专项、科技合作专项、科技平台专项5类一级专项,实行分类定位、分级管理。
为方便科研人员全面快捷了解院级科技专项信息并进行项目申报等相关操作,特搭建中国科学院院级科技专项信息管理服务平台。了解科技专项更多内容,请点击进入→

科研进展/ 更多

工作动态/ 更多



中国科学院学部
中国科学院院部

语音播报

大豆(Glycine max (L.) Merr.)是重要的粮油作物之一,其产量提升、品质改进关乎全球人口的需求和利益。高通量测序技术的发展促使大豆组学研究不断深入。实现大豆多维组学数据的整合分析,将会为大豆遗传育种提供有力支持。
近日,中国科学院遗传与发育生物学研究所田志喜团队联合北京基因组研究所(国家生物信息中心)章张、宋述慧团队,开发了大豆多维组学深度整合数据库SoyOmics。相关研究成果以SoyOmics: A deeply integrated database on soybean multi-omics为题,发表在《分子植物》(Molecular Plant)上。
SoyOmics数据库全面整合分析了大豆相关的多维组学数据。数据库目前收录了27个大豆品系的从头组装基因组数据,并对相应基因组信息进行了全面的基因组注释。该数据库以高质量的ZH13作为参考基因组,对2898份材料的全基因组测序数据进行了全基因组序列变异检测,鉴定到约3800万条SNP/INDEL变异数据,同时为每个变异位点提供多层次注释信息。除序列变异外,数据库提供了来自大豆泛基因组分析的约55万条结构变异数据以及基于结构变异构建的图泛基因组。数据库收录了来自ZH13和Williams82两个基因组27个组织时期的表达数据以及其他26个品系9个组织时期的表达数据,并展示了不同品系间同源基因的差异表达。数据库针对115个表型多年多点测定的约2.7万条表型记录进行了本体注释和归类,并将表型数据与变异数据进行关联。除以上组学数据外,数据库同时提供了部分种质资源的甲基化测序数据以及Soy40K大豆芯片数据。该数据库从基因组、变异组、转录组、表型组等不同层面整合了大豆相关数据集,实现了不同层次组学数据的交互查询和联合比较分析。
为更好服务于用户,研究团队开发了多个实用的“一站式”分析模块,支撑实现GWAS分析、表达模式分析、单倍型分析、基因组坐标转换、图泛基因组可视化等。该数据库具备多维组学数据间的深度关联性、用户的高度可交互性及分析场景的高覆盖性,预期能为大豆遗传学及育种研究提供基础数据支撑和全新的观察视角。
研究工作得到中科院战略性先导科技专项、科技创新2030-重大项目、国家自然科学基金、国家重点研发计划、博士后创新人才计划等的支持。
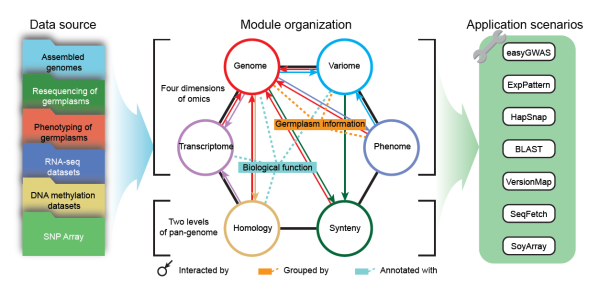
SoyOmics数据库结构框架





© 1996 - 中国科学院 版权所有 京ICP备05002857号-1  京公网安备110402500047号 网站标识码bm48000002
京公网安备110402500047号 网站标识码bm48000002
地址:北京市西城区三里河路52号 邮编:100864
电话: 86 10 68597114(总机) 86 10 68597289(总值班室)

© 1996 - 中国科学院 版权所有 京ICP备05002857号-1 京公网安备110402500047号 网站标识码bm48000002
地址:北京市西城区三里河路52号 邮编:100864
电话: 86 10 68597114(总机) 86 10 68597289(总值班室)
© 1996 - 中国科学院 版权所有
京ICP备05002857号-1京公网安备110402500047号
网站标识码bm48000002
地址:北京市西城区三里河路52号 邮编:100864
电话:86 10 68597114(总机)
86 10 68597289(总值班室)

























